机器学习数据集¶
examples/dataset/ 中的三个脚本生成大规模、可直接用于机器学习的 PDE 解批量数据,用于训练神经算子(GAOT、FNO、Transolver 等)。其方法即 批量化工作流 中所述:同一网格、多个右端项、一次分解、多右端项回代。
poisson/poisson_dataset.py—— 在圆形区域上、对随机源场生成 1000 个稳态泊松样本;这是"一次分解 / 多次回代"最简洁的示范。heat/heat_dataset.py—— 在 L 形区域上生成 1000 个热方程样本,每个 100 个时间步。wave/wave_dataset.py—— 在圆形区域上生成 1000 个波动方程样本,每个 100 个时间步。
这三个数据集用于 GAOT 论文(arXiv:2505.18781)。
当有可见的 GPU 时,这三个脚本都在 GPU 上运行,否则在 CPU 上回退到 SciPy,并对这两条路径进行相互基准测试。重点在于它有多 廉价:由于系统矩阵只分解一次,而每个样本——在瞬态情形下,每个时间步——都只是另一个右端项,因此生成一个 1000 样本的数据集,其代价仅比单次求解略多一点。下面的耗时说明了一切:1000 次稳态泊松求解只需半秒,而 1000 次各 100 步的瞬态运行(十万次线性求解)在单块 GPU 上约需十秒。
泊松方程批量右端项 —— poisson_dataset.py¶
稳态热身:一个刚度矩阵,多个源场。脚本对一个圆盘进行网格剖分(半径 \(0.5\),圆心在 \((0.5, 0.5)\),chara_length=0.008),从 PoissonMultiFrequency(K_modes=16)抽取 1000 个多频傅里叶源场,并针对单个装配好的 K 一并求解。
唯一针对泊松问题的技巧在于右端项。对于节点源,载荷 \(\int f\, v_i\,\mathrm{d}x\) 等于 \(M f\),其中质量矩阵来自相同的数值积分,因此整批载荷就是一次稀疏矩阵乘 M @ f.T:
from tensormesh import (LaplaceElementAssembler, MassElementAssembler,
Mesh, Condenser, NodeAssembler)
from tensormesh.dataset import PoissonMultiFrequency
class FAssembler(NodeAssembler): # b_i = ∫ f v_i dx
def forward(self, v, f):
return v * f
mesh = Mesh.gen_circle(chara_length=0.008, cx=0.5, cy=0.5, r=0.5).to(device)
a = torch.zeros((1000, 16, 16), device=device).uniform_(-1, 1)
eq = PoissonMultiFrequency(a=a)
f = eq.source_term(mesh.points, domain="rectangle") # [batch, n_points]
K = LaplaceElementAssembler.from_mesh(mesh)(mesh.points)
M = MassElementAssembler.from_mesh(mesh)(mesh.points)
b = M @ f.T # [n_points, batch]
condenser = Condenser(mesh.boundary_mask,
torch.zeros(mesh.n_points, device=device))
K_, b_ = condenser(K, b) # [n_inner, batch]
u_ = K_.solve(b_) # multi-RHS direct solve
u = condenser.recover(u_).T # [batch, n_points]
二维右端项的形状 [n_inner, batch] 会被自动路由到直接求解:一次分解,batch 次回代。脚本在求解前断言 M @ f.T 与逐样本的 FAssembler 载荷一致,并将 GPU 结果与一次独立的 CPU 重新装配进行交叉验证。
在 NVIDIA RTX PRO 6000 上(共 14478 个自由度,其中 14145 个内部自由度,1000 个样本),全部 1000 次求解在半秒内完成:
GPU solve (cuDSS, LDLᵀ): 0.51 s
CPU solve (SciPy, LU): 1.35 s
max |GPU − CPU|: 6.16e-17
speedup (CPU / GPU): 2.67×
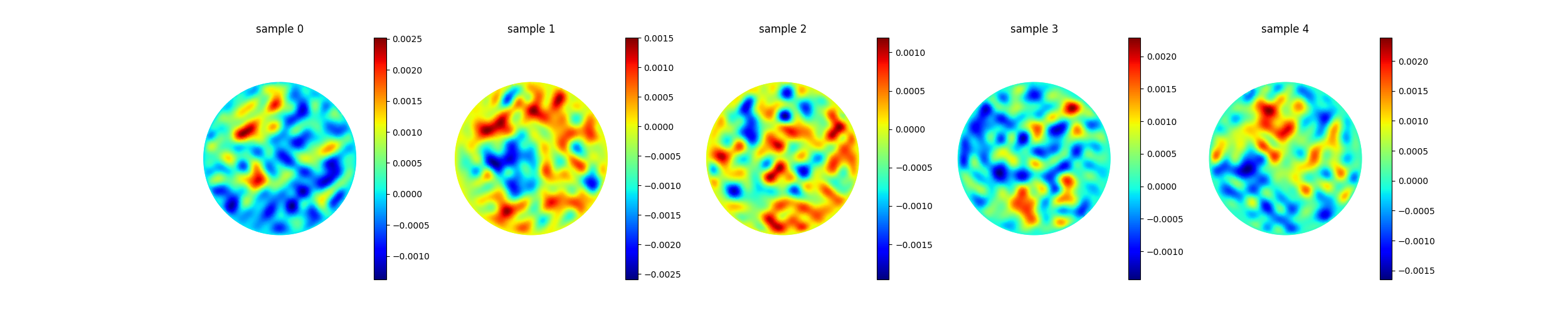
图 61 从生成的数据集中选取的五个代表性样本——圆盘上、对应五个随机多频源场的 FEM 泊松解。脚本会在生成该图的同时写出 poisson_dataset.npz(解、源、点、系数)。¶
L 形区域上的热数据集 —— heat_dataset.py¶
采用与 扩散 相同的后向欧拉格式,但时间循环作用于形状为 [n_dofs, batch_size] 的二维快照 U 上:
mesh = Mesh.gen_L(chara_length=0.008, element_type="tri").to(device)
batch_size, d, n = 1000, 16, 100
mus = torch.rand((batch_size, d)) # random Fourier coeffs
dataset = HeatMultiFrequency(mu=mus)
u0s = dataset.initial_condition(mesh.points) # [batch_size, n_dofs]
M = MAssembler.from_mesh(mesh, quadrature_order=2)()
A = AAssembler.from_mesh(mesh, quadrature_order=2)()
condenser = Condenser(mesh.boundary_mask)
dt, D = 5e-5, 1.0
K_ = condenser(M + dt * D * D * A)[0] # condense once
U = u0s.T.clone() # [n_dofs, batch_size]
Us = [U]
for _ in range(n - 1):
F = M @ U # [n_dofs, batch_size]
F_ = condenser.condense_rhs(F) # [n_inner, batch_size]
U_ = K_.solve(F_) # [n_inner, batch_size]
U = condenser.recover(U_)
Us.append(U)
让 GPU 路径变快的几处细节:
F在每一步都是二维张量;稀疏矩阵乘M @ U在 GPU 上沿批次轴进行广播。K_.solve(F_)(其中F_形状为[n_inner, batch_size])会路由到torch-sla的批量右端项直接求解路径(K_是SparseMatrix,因此.solve是继承自torch_sla.SparseTensor.solve的方法)。在 CPU 上这是 SciPy 的 LU;在 GPU 上则是 cuDSS——这里是 Cholesky 分解,因为 \(M + \Delta t\, D^2 A\) 是 SPD 的。同一次分解在全部 1000 个样本和全部 100 个时间步上被复用。L 形区域以
chara_length=0.008进行剖分,约得到 14k 个自由度——其规模足够大,使得批量直接求解远胜于 1000 次独立的逐样本求解。
输出是单个 .npz 文件,包含完整的快照张量:
heat_dataset.npz
snapshots: (100, 14052, 1000) # n_steps × n_dofs × batch_size
points: (n_dofs, 2)
mus: (1000, 16) # Fourier coefficients
dt, D, n: scalars
在 NVIDIA RTX PRO 6000 上(14052 个自由度,1000 个样本,100 步):
GPU solve (cuDSS, Cholesky): 9.20 s
CPU solve (SciPy, LU): 123.26 s
max |GPU − CPU|: 9.09e-16
speedup (CPU / GPU): 13.39×
那个 GPU 数字涵盖了 十万 次线性求解(1000 个样本 × 100 个时间步),全部共享同一次分解。
生成的热数据集中五个样本的动画。
圆盘上的波动数据集 —— wave_dataset.py¶
思路相同,采用中心差分格式。网格为一个圆形区域(圆心在 \((0.5, 0.5)\),半径 \(0.5\),chara_length=0.008),逐样本的初始条件由一个 16×16 的随机傅里叶系数矩阵 \(a\) 参数化:
batch_size, K, n = 1000, 16, 100
a = torch.zeros((batch_size, K, K)).uniform_(-1, 1)
dataset = WaveMultiFrequency(a=a, c=c)
u0s = dataset.initial_condition(mesh.points) # [batch_size, n_dofs]
形状为 [n_dofs, batch_size] 的时间循环在本质上与热方程情形完全相同,只是以波动方程的三项递推取代了欧拉步(逐样本推导参见 波动方程)。输出格式:
wave_dataset.npz
snapshots: (100, n_dofs, 1000)
points: (n_dofs, 2)
a: (1000, 16, 16)
dt, c, n: scalars
在 NVIDIA RTX PRO 6000 上(14478 个自由度,1000 个样本,100 步):
GPU solve (cuDSS, LDLᵀ): 10.53 s
CPU solve (SciPy, LU): 175.51 s
max |GPU − CPU|: 1.03e-15
speedup (CPU / GPU): 16.68×
生成的波动数据集中五个样本的动画。
运行示例¶
cd examples/dataset/poisson
python poisson_dataset.py # writes poisson_dataset.{npz,png}
cd ../heat
python heat_dataset.py # writes heat_dataset.{npz,mp4}
cd ../wave
python wave_dataset.py # writes wave_dataset.{npz,mp4}
只要 CUDA 可见,GPU 求解就由 torch-sla 自动派发(在上述硬件上为 cuDSS);后端选项参见 稀疏求解器。