分布式 FEM¶
examples/distributed/ 中的三个脚本涵盖了 TensorMesh 中多 GPU FEM 的基础构件:单元邻接图上的图着色、谱区域分解,以及在结构化四面体立方体上进行的单 GPU 与多 GPU 装配基准测试。
小心
分布式层仍在积极开发中。下面的基础构件(着色、分区、多 GPU 装配)是可用的,基准测试也是真实的,但公开 API 尚不稳定,用户指南 也有意没有将其作为一等工作流来记录。下一步是将它与 torch-sla 的分布式线性求解器耦合,使装配 和 求解都跨多块 GPU 运行——目标是攻克无法在单个设备上容纳的超大规模工业问题。在此之前,请将这里的示例视为可供学习的范例,而非稳定的接口。
单元图着色 —— graph_coloring.py¶
在 GPU 上进行无竞争的原子加装配,需要对单元邻接图进行着色:共享同一自由度的单元不能同色,这样每个颜色类才能并行地散射进全局矩阵。mesh.color() 一次调用即可完成,并在 GPU 可用时运行并行的 Welsh-Powell 式启发式算法:
from tensormesh.dataset.mesh import gen_rectangle
mesh = gen_rectangle(chara_length=1.0/50, element_type="tri")
mesh.to(device)
colors = mesh.color() # one int per element
n_colors = colors.max().item() + 1
print(f"Used {n_colors} colors.")
对于单位正方形的规则三角剖分,该算法通常找到 6–8 种颜色——接近二维三角形邻接图的最优色数。可视化按颜色类对每个单元上色,呈现出我们熟悉的条纹/带状图样。
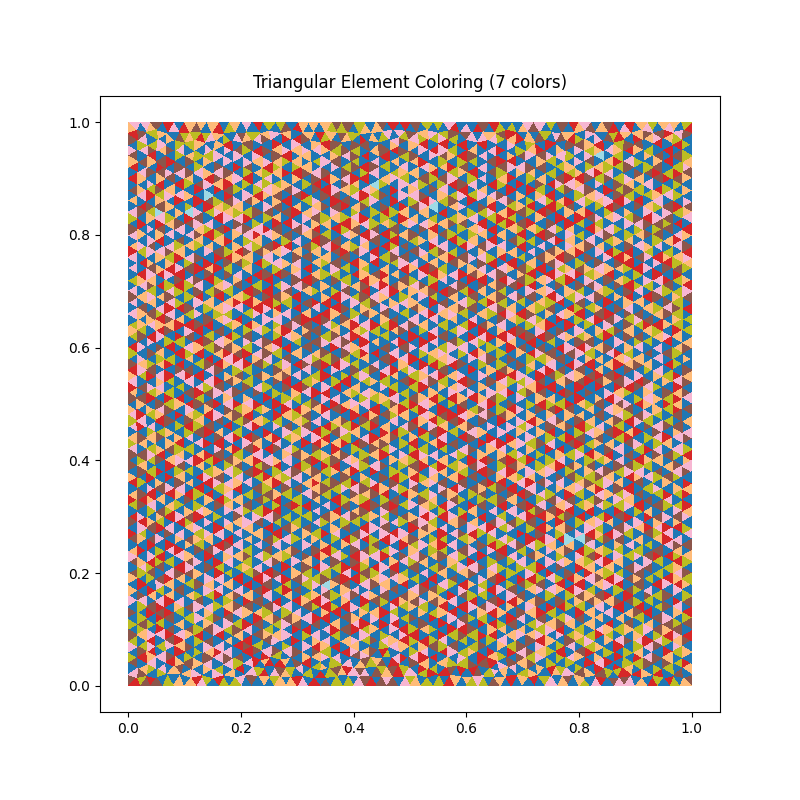
图 62 graph_coloring.py 的输出:单位正方形的三角形网格,按单元颜色类上色。Welsh-Powell 启发式算法在此找到 7 种颜色;同色的单元绝不共享节点,因此每个颜色类都可以并行装配而不会发生写冲突。¶
谱区域分解 —— graph_partition.py¶
对于多 GPU 工作,网格必须被划分为 n_parts 个界面较小且均衡的子区域。带 method="spectral" 的 partition_mesh 会计算图拉普拉斯算子的 Fiedler 向量并递归二分:
from tensormesh.mesh.partition import partition_mesh
submeshes = partition_mesh(mesh, n_parts=4, method="spectral")
返回的 Mesh 对象列表中,每一个都携带 幽灵节点——同属两个子区域的边界节点会被复制,其原始的全局 ID 存储在 submesh.point_data["orig_nid"] 中。脚本的爆炸视图可视化在空间上分开这四个子区域,并圈出共享的界面节点——这正是你通常要在白板上画出来才能讲清楚区域分解的那张几何图。
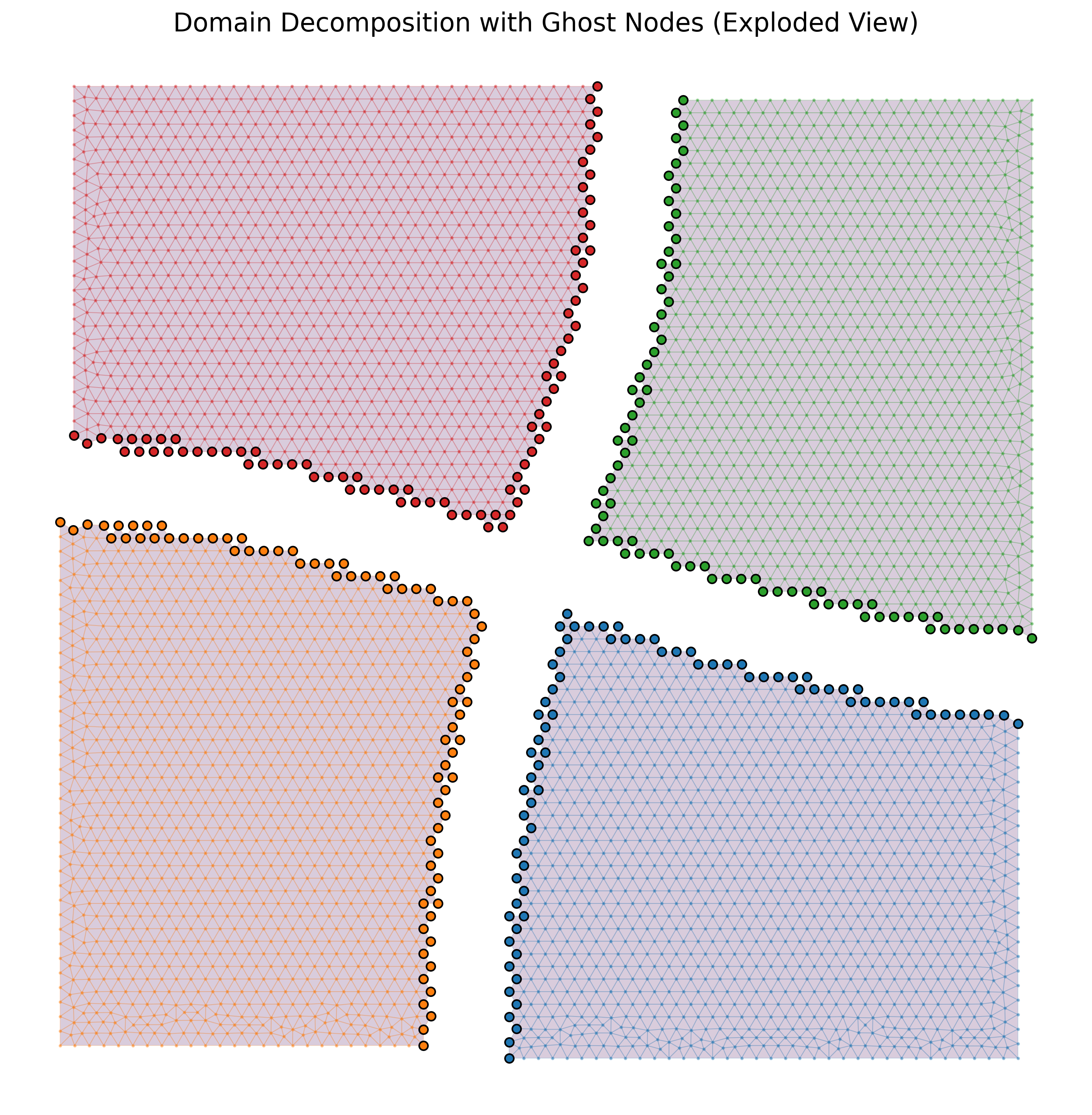
图 63 graph_partition.py 的输出:单位正方形的四路谱分区,以爆炸视图呈现。每个子区域以各自的颜色渲染;沿每个子区域共享边界处高亮的圆点即 幽灵节点——界面顶点的复制副本,由每个进程在本地持有,其原始全局 ID 保存在 submesh.point_data["orig_nid"] 中。¶
多 GPU 装配基准测试 —— benchmark_assembly.py¶
重头戏式的分布式 FEM 基准测试。一个含 \((n+1)^3\) 个点和 \(5 n^3\) 个四面体的结构化四面体立方体被装配 (i) 在单块 GPU 上,(ii) 通过 torch.multiprocessing 跨所有可见的 GPU 上。驱动程序从一个可配置的起始规模开始扫描 \(n\),直到任一路径耗尽内存为止。
有趣的机制都在 DistributedMesh 中,它将谱分区 + 逐子区域的幽灵节点记账封装进单个对象:
import torch.multiprocessing as mp
from tensormesh.distributed import DistributedMesh
def _mp_assemble_worker(rank, submesh, device_id, q_order, return_dict):
device = torch.device(f"cuda:{device_id}")
torch.cuda.set_device(device)
submesh.to(device)
asm = tm.LaplaceElementAssembler.from_mesh(
submesh, quadrature_order=q_order
)
K_local = asm()
# …translate K_local.row/col through orig_nid into global indices…
dmesh = DistributedMesh(mesh, num_partitions=num_partitions)
manager = mp.Manager(); return_dict = manager.dict()
procs = [
mp.Process(target=_mp_assemble_worker,
args=(i, dmesh.submeshes[i], i, q_order, return_dict))
for i in range(num_partitions)
]
for p in procs: p.start()
for p in procs: p.join()
几处要紧的细节:
每块 GPU 一个进程。 配合
set_start_method("spawn")的torch.multiprocessing让每个进程拥有自己的 Python 解释器,从而绕开 GIL。对于受 CPU 限制的装配,多线程无济于事。幽灵节点记账。 每个工作进程装配一个 局部
SparseMatrix,其行/列为局部自由度索引;驱动程序在拼接这些部分矩阵之前,通过orig_nid将它们转换为全局索引。用户可见的开销是每个工作进程一次 GPU→CPU 拷贝。单卡内存。 基准测试的"mem save"列报告
single_gpu_peak / max_per_card_peak——对于装配步骤本身,该值通常接近num_partitions,因为每个工作进程只存储自己的子区域。
输出表格的一段代表性片段:
n | Points | Tets | 1-GPU time | 1-GPU mem | N-GPU wall N-GPU max_t N-GPU mem/card | Speedup Mem save
----------------------------------------------------------------------------------------------------------------
30 | 29,791 | 135,000 | 0.42 s | 0.5 GB | 0.18 s 0.11 s 0.16 GB | 2.3x 3.1x
50 | 132,651 | 625,000 | 1.90 s | 2.3 GB | 0.55 s 0.34 s 0.62 GB | 3.5x 3.7x
… … … … … … … … … …
命令行接口:
python benchmark_assembly.py # auto-detect GPUs
python benchmark_assembly.py --partitions 4 --start 30 --max 200
运行示例¶
cd examples/distributed
python graph_coloring.py # writes graph_coloring_result.png
python graph_partition.py # writes graph_partition_exploded.png
python benchmark_assembly.py # prints benchmark table
这三个脚本都很轻量,可在单台工作站上运行;只有 benchmark_assembly.py 能从多块 GPU 中获益。
下一步¶
核心概念 —— 模块图谱中将
tensormesh.distributed作为一条研究路径提及。批量化工作流 —— 在动用多 GPU 之前往往已经够用的单 GPU 批量化模式。
基础与可视化 ——
plot_mesh.py提供了这些算法所作用的邻接图可视化。