波动方程¶
单个脚本 examples/wave/wave.py 在单位正方形上以显式中心差分时间步进求解线性标量波动方程。它是 扩散 中热传导示例的经典双曲型对应。
强形式为
初始条件取自 WaveMultiFrequency 的多频傅里叶级数,初速度为零。脚本以 \(c = 2.0\)、\(\Delta t = 10^{-3}\) 运行 100 步。
中心差分时间步进¶
标准的时间离散为
其中 \(M\) 是质量矩阵,\(A\) 是拉普拉斯刚度。这在时间上是显式的——每一步只需对一个固定的质量矩阵求解,因此“分解一次 / 多次回代”才是正确的模式。
第一步需要特殊处理,因为 \(U^{-1}\) 未知;利用泰勒展开 \(U^{-1} \approx U^{0} - \Delta t\, V^{0}\) 以及初始条件 \(V^{0} = 0\),得到
TensorMesh 设置¶
两个极小的装配器(一个用于 \(M\),一个用于 \(A\))、一个用于齐次狄利克雷边界条件的 Condenser,以及一个 15 行的时间循环。注意那个对 SparseMatrix 做缩放、同时保持 SparseMatrix 类型的小辅助函数:
class AAssembler(ElementAssembler):
def forward(self, gradu, gradv): return gradu @ gradv
class MAssembler(ElementAssembler):
def forward(self, u, v): return u * v
def scale_matrix(mat, s):
return SparseMatrix(mat.edata * s, mat.row, mat.col, mat.shape)
mesh = Mesh.gen_rectangle(chara_length=0.01).to(device)
dataset = WaveMultiFrequency(K=16, c=c)
M = MAssembler.from_mesh(mesh, quadrature_order=2)()
A = AAssembler.from_mesh(mesh, quadrature_order=2)()
condenser = Condenser(mesh.boundary_mask)
u0 = dataset.initial_condition(mesh.points).to(device)
v0 = torch.zeros_like(u0)
# First step: 2 M U^1 = 2 M U^0 - dt^2 c^2 A U^0
cA = scale_matrix(A, c * c)
K = scale_matrix(M, 2.0)
F = -(dt*dt) * (cA @ u0) + 2.0 * (M @ u0) + (2.0 * dt) * (M @ v0)
K_, F_ = condenser(K, F)
U1 = condenser.recover(K_.solve(F_))
M_ = scale_matrix(K_, 0.5) # K_ = 2 M_ → M_ = K_/2
Us = [u0, U1]
for _ in range(n - 2):
U_prev, U_curr = Us[-2], Us[-1]
F = 2.0*(M @ U_curr) - (M @ U_prev) - (dt*dt) * (cA @ U_curr)
F_ = condenser.condense_rhs(F)
U_ = M_.solve(F_)
Us.append(condenser.recover(U_))
几点实用说明:
稳定性。 中心差分是条件稳定的——\(\Delta t \lesssim h / c\)。脚本所取的参数(\(\Delta t = 10^{-3}\)、\(h = 0.01\)、\(c = 2\))能轻松满足该条件。
分解一次。
M_(凝聚后的质量矩阵)从第一步的矩阵中恢复,并在每次循环迭代中重复使用;只有右端项发生变化。支持 GPU。 脚本在可用时选择
cuda,mesh.to(device)一次调用即可将整个网格及缓冲区移动过去。快照仅在最后为可视化才移回 CPU。
如需使用高阶时间积分器(Newmark、龙格-库塔),可直接换用 ExplicitRungeKutta(来自 tensormesh.ode)—— 参见 时间积分。
``wave.py`` 的输出:单位正方形上多频驻波的有限元预测(左)与解析解(右)对比。在整个运行过程中,相位和振幅都紧跟解析参考解;只要满足 CFL 条件,中心差分就能保持能量守恒。
能量守恒¶
无阻尼波动方程守恒机械能
其中速度 \(v = u_t\) 取为所存储位移历史的中心差分。wave.py 在每一步都计算它并写出 wave_energy.png——这是对时间步进的直接检验,因为只要 CFL 条件成立,中心差分格式就能在 \(\mathcal{O}(\Delta t^2)\) 精度内守恒一个离散能量。
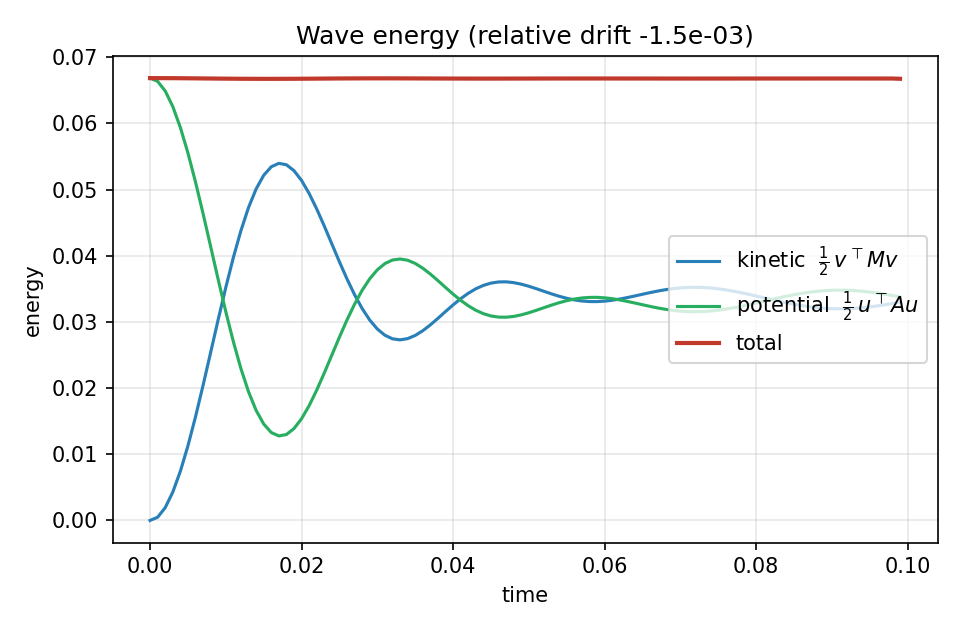
图 41 动能与势能反相交换,而总能量(红色)保持平直:100 步运行中的相对漂移约为 \(1.5\times10^{-3}\)。运动起始时为纯势能(初速度为零),随着驻波形成而趋于能量均分。¶
运行示例¶
cd examples/wave
python wave.py # writes wave.mp4 (FEM vs analytical) and wave_energy.png