时间积分¶
瞬态问题 —— 热传导、波动、瞬态弹性、相场动力学 —— 通过一个时间步进循环对静态 FEM 流程进行扩展。一旦质量矩阵和刚度矩阵装配完成,半离散的弱形式就只是一个关于节点值的常微分方程组
而本章的任务就是将 u 从一个时间层准确且稳定地推进到下一个时间层,同时保持一切可微。
TensorMesh 提供了两种互补的风格:
手动时间步进循环。 你自己装配出经时间步进处理后的算子,为边界条件调用一次
Condenser,并编写一个 Pythonfor循环,每步执行一次线性求解。这种方式简短、直观,是处理一次性问题阻力最小的途径。tensormesh.ode中的积分器类。你重写forward(t, u)(显式)或forward_M/forward_A/forward_B(线性隐式),然后调用step(t, u, dt)。当你想要一个通用的瞬态驱动器,可以在不重写循环的情况下将一种格式换成另一种时,这很有用。线性隐式族通过三个边界条件钩子与Condenser组合(参见 与边界条件组合),因此狄利克雷自由度的静态凝聚在积分器内部同样有效。
两种风格都与 torch.autograd 组合,因此梯度会反向流经每一步,回传到初始条件、材料参数和边界数据中(参见 可微性)。
积分器目录¶
tensormesh.ode 提供了三种具体格式以及两个可扩展的基类:
类 |
阶数 |
形式 |
适用场景 |
|---|---|---|---|
1 |
\(\dot u = f(t, u)\) |
廉价的显式右端项;适用于 CFL 限制以下的非刚性问题。 |
|
1 |
\(M\dot u = A u + B\) |
热传导 / 扩散 / 刚性系统。无条件稳定。 |
|
2 |
\(M\dot u = A u + B\) |
同一族,二阶精度(梯形法则)。 |
|
s 级 |
\(\dot u = f(t, u)\) |
基类 —— 提供你自己的 Butcher 表 |
|
s 级 |
\(M\dot u = A u + B\) |
同样,适用于线性隐式格式。 |
对于显式族,你重写 forward(t, u) 来返回右端项 \(f(t, u)\)。对于线性隐式族,你重写三个方法,分别返回当前时刻的算子:
class MyScheme(ImplicitLinearEuler):
def forward_M(self, t): return M_matrix # SparseMatrix, Tensor, or scalar
def forward_A(self, t): return -K_matrix # SparseMatrix, Tensor, or scalar
def forward_B(self, t): return 0.0 # Tensor or scalar
返回标量时,它会被提升为该倍数的单位矩阵(对于 B 则提升为常向量),因此你可以让这三者中的任意一个保持其默认值 1、1、0。每次调用 step(t0, u0, dt) 都会返回推进一个时间步后的新 u;u 必须是一维的([D]),因此在步进之前请先将向量值问题展平。
实例 1:一个标量常微分方程¶
积分器类处理普通常微分方程的方式与处理 FEM 系统的方式相同 —— 你只需将算子保留为标量即可。以
为例,其精确解为 \(u(t) = e^{-\lambda t}\)。ImplicitLinearEuler(一阶)和 MidPointLinearEuler(二阶)都接受标量 M = 1 和 A = -\lambda,因此驱动器是两个简短的类:
import torch
from tensormesh.ode import ImplicitLinearEuler, MidPointLinearEuler
class ScalarIE(ImplicitLinearEuler):
def __init__(self, lam):
super().__init__()
self.lam = lam
def forward_M(self, t): return 1.0
def forward_A(self, t): return -self.lam
def forward_B(self, t): return 0.0
class ScalarMP(MidPointLinearEuler):
def __init__(self, lam):
super().__init__()
self.lam = lam
def forward_M(self, t): return 1.0
def forward_A(self, t): return -self.lam
def forward_B(self, t): return 0.0
lam = torch.pi ** 2
u = torch.ones(1, dtype=torch.float64)
dt = 1e-3
integrator = ScalarMP(lam)
for k in range(50):
u = integrator.step(k * dt, u, dt)
在不断减小的 \(\Delta t\) 下运行同一问题,并在 \(T = 0.05\) 处测量误差,会得到教科书式的一阶和二阶斜率:
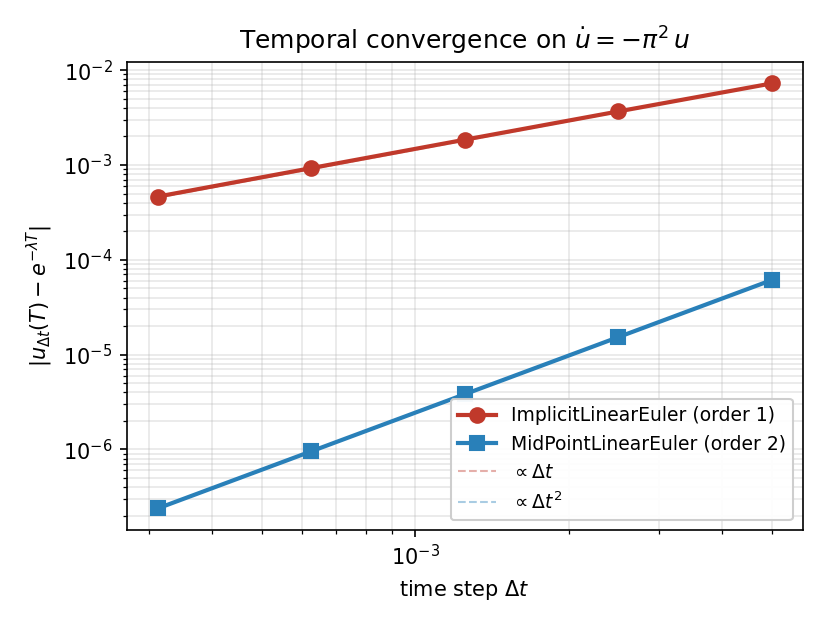
图 11 ImplicitLinearEuler 和 MidPointLinearEuler 在 \(\dot u = -\pi^{2}\,u\) 上的终点误差随 dt 变化的关系。虚线参考线的斜率分别为 1 和 2。¶
实际的解读是:采用更高阶的方法,可以在 相同 的步长下换取数量级的精度提升 —— 在 dt = 5e-3 时,中点法则已经比后向欧拉法高出四个数量级。
实例 2:二维热方程¶
对于带狄利克雷边界的 FEM 问题,手动循环是最简洁的模式。求解
半离散形式为 \(M\dot u = -\kappa\,K\,u\),一个后向欧拉步给出线性系统
完整的驱动器只装配一次 M 和 K,只构建一次经时间步进处理后的算子,只对其凝聚一次,然后进入循环:
import torch
from tensormesh import (Mesh, ElementAssembler,
MassElementAssembler, LaplaceElementAssembler,
Condenser)
mesh = Mesh.gen_rectangle(chara_length=0.025, order=1)
M = MassElementAssembler.from_mesh(mesh)().double()
K = LaplaceElementAssembler.from_mesh(mesh)().double()
kappa = 1.0
dt = 5e-4
# Build the time-stepped operator once and condense it once.
A = M + dt * kappa * K
condenser = Condenser(mesh.boundary_mask)
A_in, _ = condenser(A, torch.zeros(mesh.n_points, dtype=torch.float64))
# Initial condition (already zero on the Dirichlet boundary).
x, y = mesh.points.double()[:, 0], mesh.points.double()[:, 1]
u = torch.sin(torch.pi * x) * torch.sin(torch.pi * y)
# Time stepping: each iteration is one mass-vector product,
# one RHS condensation, one back-substitution, one recovery.
snapshots = [u]
for _ in range(100):
f = M @ u
f_in = condenser.condense_rhs(f)
u_in = A_in.solve(f_in)
u = condenser.recover(u_in)
snapshots.append(u)
使这个循环变快的两个要素是:(a)只对经时间步进处理后的算子分解一次 —— 每步的求解只是通过 A_in 进行一次回代 —— 以及(b)通过 condense_rhs() 复用缓存的凝聚器布局。两者结合,将一个看似 \(N^{3}\) 阶的问题变成了一个 \(N\) 阶的内层循环。
解以 \(e^{-2\pi^{2}t}\) 的形式指数衰减:
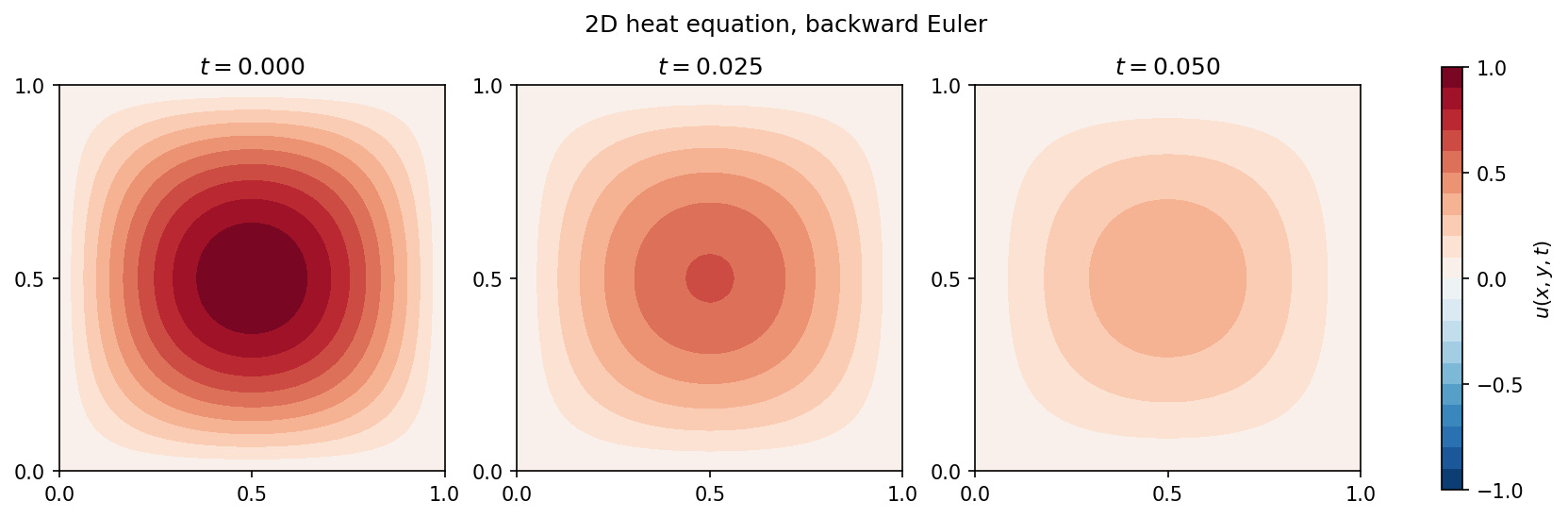
图 12 \(u(x, y, t)\) 在 \(t = 0\)、\(t = T/2\) 和 \(t = T\)(其中 \(T = 0.05\))处的快照,采用后向欧拉法,\(\Delta t = 5\!\times\!10^{-4}\),特征网格尺寸 \(h = 0.025\)。¶
如需动画版本,请参见 示例画廊 中渲染好的 heat.mp4,或源码树中 examples/diffusion/heat/ 下的文件。
自定义 Butcher 表¶
两个 RungeKutta 基类允许你提供任意 Butcher 表。要在 \(\dot u = f(t, u)\) 上使用经典的四阶显式龙格-库塔法:
import torch
from tensormesh.ode import ExplicitRungeKutta
a = torch.tensor([[0., 0., 0., 0.],
[0.5, 0., 0., 0.],
[0., 0.5, 0., 0.],
[0., 0., 1., 0.]])
b = torch.tensor([1/6, 1/3, 1/3, 1/6])
class MyRK4(ExplicitRungeKutta):
def forward(self, t, u):
return f(t, u) # your problem-specific RHS
integrator = MyRK4(a, b)
for k in range(n_steps):
u = integrator.step(k * dt, u, dt)
该类会验证 a 是下三角的,并且 \(\sum_i b_i = 1\)(在浮点容差范围内),从而让你尽早发现誊写错误。对 ImplicitLinearRungeKutta 采用同样的模式,可以得到对角隐式或全隐式格式 —— 提供一个非零对角线,该类便会为你装配并求解分块的级系统。
与边界条件组合¶
在 TensorMesh 中,通过 Condenser 进行静态凝聚(参见 边界条件)是施加狄利克雷条件的推荐方式。两种时间积分风格都支持它;唯一的区别在于这三个凝聚器调用 放在哪里。
心智模型 —— 每次求解究竟 为了什么
这两种风格的区别在于 线性求解到底在求解什么,而这一点就决定了哪些 Condenser 调用才是正确的:
手动循环 → 未知量是 状态 \(u^{n+1}\)。它在边界上取规定值 \(u_o\),因此你使用感知边界值的调用(
condense_rhs会减去 \(K_{io}\,u_o\);recover会将 \(u_o\) 写回边界位置)。积分器钩子 → 未知量是 级斜率 \(k_i \approx \dot u\)。狄利克雷自由度在时间上是固定的,因此无论 \(u_o\) 是多少,那里都有 \(\dot u = 0\) —— 斜率在边界上为零。你使用与边界值无关的投影(
restrict/prolong,它们在两个方向上都在边界处取零)。
全自由度状态的边界值由 \(u_0\) 通过 RK 更新 \(u_{n+1} = u_0 + h\sum_i b_i k_i\) 一路携带;它 不会 被级恢复重新施加。
一目了然地,相同的三个操作在两种风格之间的对应关系如下 —— 本节其余部分只是每一行背后的细节:
操作 |
手动循环(状态 \(u\)) |
积分器钩子(斜率 \(k\)) |
|---|---|---|
凝聚算子 |
在循环之前 |
|
将右端项投影下去 |
|
|
将解提升回去 |
|
|
在手动循环中¶
这一模式与 实例 2 中使用的相同:
在循环之前调用
condenser(A, _)一次,以在内部自由度上对经时间步进处理后的算子进行分解;每一步 调用
condenser.condense_rhs(f),将新的右端项投影到内部;在每次求解后调用
condenser.recover(u_in),把边界值重新拼接回去。
对于随时间变化的边界数据,可在步与步之间用 update_dirichlet() 换入新值 —— 稀疏布局是缓存的,并能在更新后保留下来,因此这个调用很廉价。
通过积分器类¶
ImplicitLinearRungeKutta(及其具体子类)公开了三个钩子,step() 方法会在恰当的位置调用它们,以使静态凝聚端到端地工作。每个钩子默认都是空操作 —— 只重写你需要的那些即可。
钩子 |
由 |
对于基于 |
|---|---|---|
|
级系统的每个 |
凝聚后的内部块, |
|
每个级的右端项一次 |
向内部自由度的 限制, |
|
每个级一次,在求解之后 |
向全自由度的延拓,且边界位置取零, |
第四个钩子 post_solve(u) 在级斜率已经被提升并与 \(u_0\) 组合之后运行,因此当它接触到 u 时,u 始终是全自由度的。请将它用于作用在最终状态上的操作(裁剪、归一化、投影到流形上),而不是用于边界恢复。
这同样的三个钩子无需改动即可覆盖多级格式:step() 每个级调用它们一次(pre_solve_lhs 每个 [i][j] 块一次),因此一个 MidPointLinearEuler 或自定义的 ImplicitLinearRungeKutta 表,其接线方式与下面的后向欧拉示例完全相同。
把它们组合起来,一个热方程驱动器就变成了:
import torch
from tensormesh import (Mesh, MassElementAssembler,
LaplaceElementAssembler, Condenser)
from tensormesh.ode import ImplicitLinearEuler
class HeatStepper(ImplicitLinearEuler):
"""M du/dt = -kappa^2 K u, homogeneous Dirichlet via Condenser."""
def __init__(self, M, K, kappa, condenser):
super().__init__()
self._M, self._A, self._cd = M, -kappa * kappa * K, condenser
def forward_M(self, t): return self._M
def forward_A(self, t): return self._A
def forward_B(self, t): return 0.0
def pre_solve_lhs(self, K): return self._cd(K)[0] # condense stage block
def pre_solve_rhs(self, f): return self._cd.restrict(f) # NOT condense_rhs
def recover_stage(self, k): return self._cd.prolong(k) # NOT recover
# Same mesh and initial condition as Worked example 2.
mesh = Mesh.gen_rectangle(chara_length=0.025, order=1)
M = MassElementAssembler.from_mesh(mesh)().double()
K = LaplaceElementAssembler.from_mesh(mesh)().double()
stepper = HeatStepper(M, K, kappa=1.0,
condenser=Condenser(mesh.boundary_mask))
x, y = mesh.points.double()[:, 0], mesh.points.double()[:, 1]
u = torch.sin(torch.pi * x) * torch.sin(torch.pi * y)
dt = 5e-4
for step in range(100):
u = stepper.step(step * dt, u, dt)
examples/diffusion/heat/ 目录提供了两个版本:heat.py(手动循环)和 heat_ode.py(积分器类)。它们生成的快照在机器精度内完全相同 —— 不妨并排试一试。
为什么用 restrict / prolong 而非 condense_rhs / recover¶
这两个积分器钩子作用于 级斜率 \(k_i \approx \dot u\),而非状态 \(u\) 本身。在狄利克雷自由度处,\(u\) 在时间上保持固定,因此 无论 规定值为何,那里都有 \(\dot u = 0\)。Condenser 上那两个感知边界值的方法是为状态而设计的:
condense_rhs()从内部右端项中减去 \(K_{io}\,u_o\),以计入状态所规定的边界值;recover()将 \(u_o\) 写入提升后解的边界位置。
在凝聚状态空间系统(即手动循环)时使用它们。而对于积分器内部的级斜率,则使用与边界值无关的投影 restrict() 和 prolong(),它们在两个方向上都在边界处取零。对于齐次狄利克雷(此时 \(u_o = 0\)),二者的差别会消失;但一旦规定值非零,差别就立刻显现出来。
在齐次狄利克雷条件下这个 bug 不可见
当 \(u_o = 0\) 时,混用这两对方法毫无代价,而这恰恰是它能蒙混过关的原因。把它改成非零,问题就会立刻显现。取上面的热传导问题,但将整个边界固定在 \(u_o = 1\)(内部从零开始),采用后向欧拉法,\(\Delta t = 10^{-2}\),40 步,并以手动状态空间循环(condense_rhs / recover)作为参考进行测量:
钩子接线 |
内部误差(相对参考) |
边界(应保持 |
|---|---|---|
|
|
|
|
|
|
|
|
40 步后为 |
condense_rhs 会减去一个斜率右端项从未有过的 \(-K_{io}\,u_o\) 项,污染了内部解。recover 会把 \(u_o\) 写入斜率的边界位置,于是 RK 更新 每 步都向边界加上 \(h\,u_o\)(此处漂移为 \(40 \times 10^{-2} \times 1 = 0.4\)),破坏了 \(u_{n+1} = u_n + h\sum_i b_i k_i\)。restrict / prolong 这一对则能在机器精度内重现手动循环。
显式格式¶
ExplicitRungeKutta 没有线性求解,因此也没有凝聚钩子。施加边界条件的自然位置是在用户提供的 forward(t, u) 内部:返回带有 f[boundary] = 0 的 \(f\),更新 \(u_{n+1} = u_n + h \sum_i b_i k_i\) 便会自动保持 \(u_{\text{boundary}}\)。
import torch
from tensormesh import Mesh, MassElementAssembler, LaplaceElementAssembler
from tensormesh.ode import ExplicitEuler
mesh = Mesh.gen_rectangle(chara_length=0.08, order=1)
M = MassElementAssembler.from_mesh(mesh)().double()
K = LaplaceElementAssembler.from_mesh(mesh)().double()
bmask = mesh.boundary_mask
class HeatExplicit(ExplicitEuler):
"""du/dt = M^{-1}(-kappa^2 K u), homogeneous Dirichlet."""
def forward(self, t, u):
f = M.solve(-(K @ u)) # semi-discrete RHS (lump M in production)
f[bmask] = 0.0 # Dirichlet DOFs have zero time-derivative
return f
x, y = mesh.points.double()[:, 0], mesh.points.double()[:, 1]
u = torch.sin(torch.pi * x) * torch.sin(torch.pi * y)
dt = 5e-5 # explicit -> small (CFL-limited) step
for step in range(50):
u = HeatExplicit().step(step * dt, u, dt)
由于边界斜率被强制为零,u 会自然而然地保持在其初始边界值(此处为 0)。对于随时间变化的狄利克雷数据,请将解析的 \(\dot u_{\text{b}}(t)\) 写入 f[boundary] 而非零,或在两次 step() 调用之间覆盖 u 的边界位置。
可微性¶
每一步都建立在可微的求解之上(参见 稀疏求解器),因此对一次瞬态模拟进行反向传播是一件水到渠成的事:
kappa = torch.tensor(1.0, requires_grad=True)
u = run_heat_solver(mesh, kappa, dt=5e-4, n_steps=100)
loss = (u - u_target).pow(2).sum()
loss.backward()
print(kappa.grad) # gradient through 100 implicit solves
正是这一点使得瞬态反问题、参数辨识以及基于梯度的偏微分方程设计在 TensorMesh 中变得直截了当 —— 完整的来龙去脉请参见 可微性。