岩土力学:Drucker-Prager 三轴压缩¶
本示例在固体力学示例族中引入一个小型岩土力学应用。它使用 TensorMesh 的公共 Drucker-Prager API —— DruckerPragerPlasticity 装配器、FrictionalMaterial 容器,以及本构原语 drucker_prager_yield_value() —— 驱动压力相关的土体或软岩材料经历一条简单的三轴压缩应变路径。
目标刻意保持适度:在一个极简驱动上演示 TensorMesh 的岩土力学约定。示例脚本位于 examples/solid/geomechanics/drucker_prager_triaxial/drucker_prager_triaxial.py。
问题¶
模型为小应变、关联 Drucker-Prager 塑性,并带有线性各向同性硬化。TensorMesh 内部保持固体力学约定:应力以受拉为正。为便于岩土力学报告,脚本将轴向应力和平均压力以受压为正的形式输出。
屈服函数在内部写为
其中
由于在受拉为正约定下受压会导致 I1 为负,更高的围压会降低 f 并延迟屈服。
历史变量¶
该内置装配器遵循与 J2 塑性模型相同的生命周期:
逐求积点历史变量存储在
model.history[etype]中;上一步的
eps_p和alpha通过element_data传入(经由model.element_data_from_history());update_state(u)在每个收敛的载荷步结束后,于torch.no_grad()上下文中被调用。
合理性检验¶
运行两种围压水平:
p0 = 0 kPa;p0 = 100 kPa。
脚本验证更高围压的情况更晚到达弹性试探屈服面,且提交的塑性历史变量是单调的。
运行¶
cd examples/solid/geomechanics/drucker_prager_triaxial
python drucker_prager_triaxial.py
若仅进行快速数值计算而不输出图像:
python drucker_prager_triaxial.py --no-plot --steps 16
默认运行会写入 drucker_prager_triaxial.png,其中包含轴向应力与塑性历史曲线。
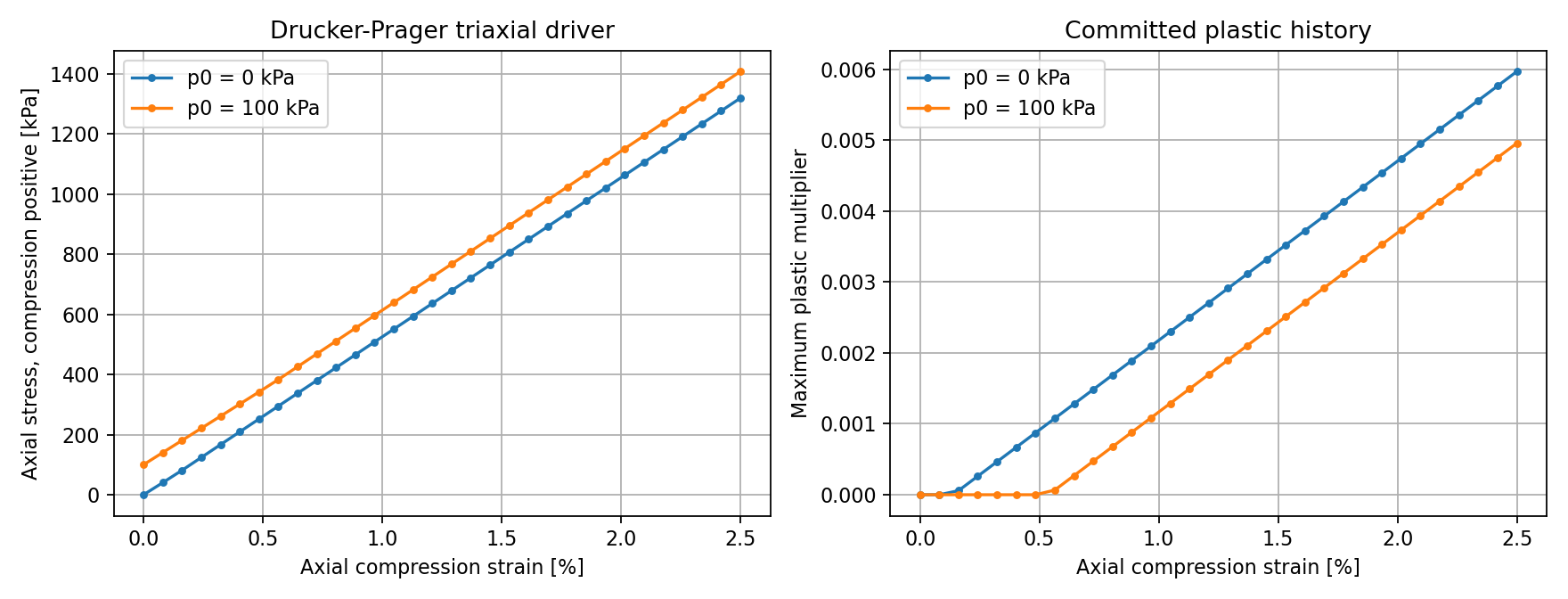
图 56 drucker_prager_triaxial.py 的输出。左面板显示压缩为正的轴向应力响应;右面板显示提交的塑性历史变量。围压更高的情形屈服更晚,符合压力相关的 Drucker-Prager 合理性检验。¶
核心实现¶
该驱动构建一个 FrictionalMaterial,装配内置的 DruckerPragerPlasticity 模型,并在用 update_state 提交历史的同时步进应变路径:
def run_case(
confinement_pressure: float,
material: FrictionalMaterial,
n_steps: int = 32,
axial_strain_final: float = -0.025,
chara_length: float = 0.75,
) -> Dict[str, List[float]]:
"""Run one displacement-controlled triaxial-compression case."""
dtype = torch.float64
device = torch.device("cpu")
mesh = gen_cube(
left=0.0,
right=1.0,
bottom=0.0,
top=1.0,
front=0.0,
back=1.0,
chara_length=chara_length,
)
mesh.points = mesh.points.to(device=device, dtype=dtype)
model = DruckerPragerPlasticity.from_mesh(mesh, material=material)
points = mesh.points
result: Dict[str, List[float]] = {
"axial_strain": [],
"axial_stress_compression_kpa": [],
"mean_pressure_compression_kpa": [],
"alpha_max": [],
"elastic_trial_f_kpa": [],
}
for axial_strain_value in torch.linspace(0.0, axial_strain_final, n_steps, device=device, dtype=dtype):
eps_diag = triaxial_strain_path(axial_strain_value, confinement_pressure, material)
u = affine_displacement(points, eps_diag).detach().clone().requires_grad_(True)
energy = model.energy(
point_data={"displacement": u},
element_data=model.element_data_from_history(),
)
# Calling backward confirms the potential is differentiable, even though
# this affine driver has no unconstrained degrees of freedom to optimize.
if energy.requires_grad:
energy.backward()
model.update_state(u)
sigma = model.mean_stress(u)
p_comp = -sigma.trace() / 3.0
sigma_axial_comp = -sigma[2, 2]
f_elastic = elastic_trial_yield_value(eps_diag, material)
result["axial_strain"].append(float(-axial_strain_value))
result["axial_stress_compression_kpa"].append(float(sigma_axial_comp / 1.0e3))
result["mean_pressure_compression_kpa"].append(float(p_comp / 1.0e3))
result["alpha_max"].append(float(model.max_alpha()))
result["elastic_trial_f_kpa"].append(float(f_elastic / 1.0e3))
return result