Geomechanics: Drucker-Prager triaxial compression¶
This example introduces a small geomechanics application inside the solid-mechanics
example family. It uses TensorMesh’s public Drucker-Prager API — the
DruckerPragerPlasticity assembler, the
FrictionalMaterial container, and the constitutive
primitive drucker_prager_yield_value() — to drive a
pressure-dependent soil or weak-rock material through a simple triaxial-compression
strain path.
The goal is deliberately modest: demonstrate TensorMesh conventions for
geomechanics on a minimal driver. The example script lives in
examples/solid/geomechanics/drucker_prager_triaxial/drucker_prager_triaxial.py.
Problem¶
The model is small-strain, associated Drucker-Prager plasticity with linear isotropic hardening. TensorMesh keeps the internal solid-mechanics convention stress tension-positive. For geomechanics reporting, the script prints axial stress and mean pressure as compression-positive quantities.
The yield function is written internally as
where
Because compression gives negative I1 in the tension-positive convention,
higher confinement lowers f and delays yielding.
History variables¶
The built-in assembler follows the same lifecycle as the J2 plasticity model:
per-quadrature history variables are stored in
model.history[etype];previous-step
eps_pandalphaare passed throughelement_data(viamodel.element_data_from_history());update_state(u)is called after each converged load step undertorch.no_grad().
Sanity check¶
Two confinement levels are run:
p0 = 0 kPa;p0 = 100 kPa.
The script checks that the higher-confinement case reaches the elastic trial yield surface later and that the committed plastic history variable is monotonic.
Running it¶
cd examples/solid/geomechanics/drucker_prager_triaxial
python drucker_prager_triaxial.py
For a fast numerical-only run without writing the plot:
python drucker_prager_triaxial.py --no-plot --steps 16
The default run writes drucker_prager_triaxial.png with axial stress and
plastic-history curves.
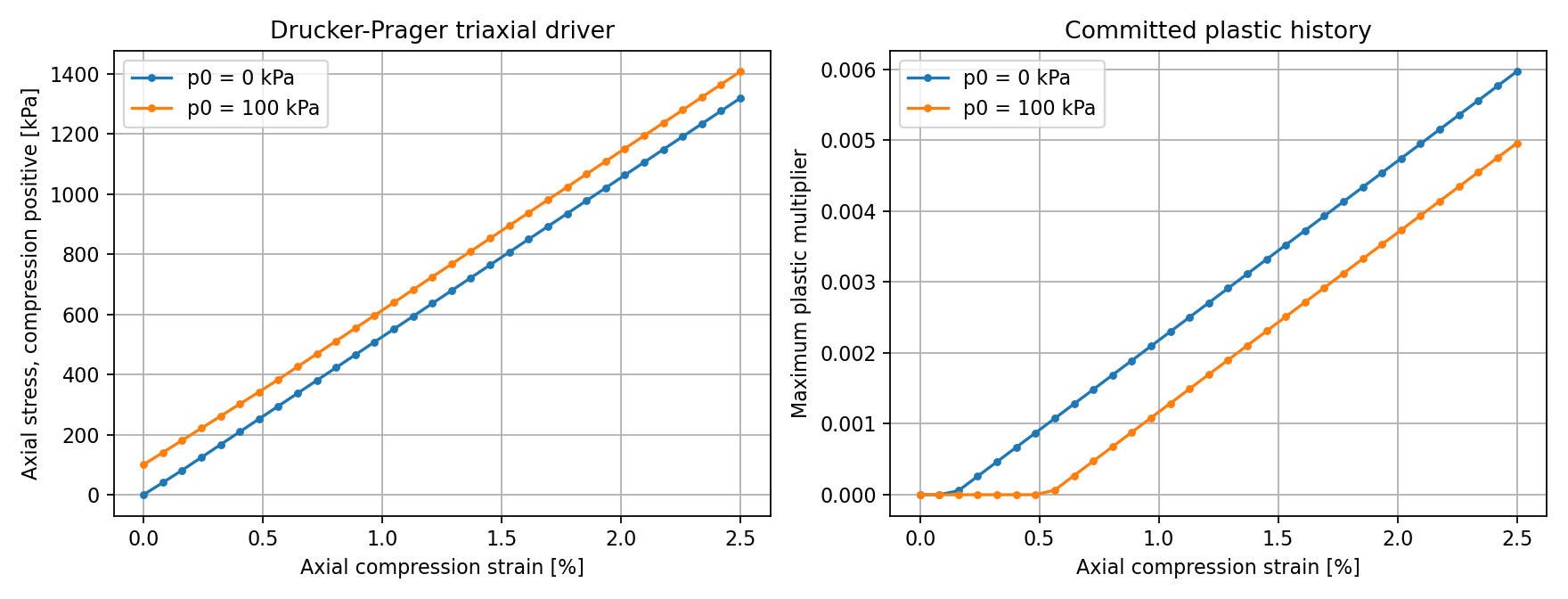
Fig. 56 Output of drucker_prager_triaxial.py. The left panel shows the
compression-positive axial stress response; the right panel shows the
committed plastic history variable. The higher-confinement case yields
later, matching the pressure-dependent Drucker-Prager sanity check.¶
Core implementation¶
The driver builds a FrictionalMaterial, assembles
the built-in DruckerPragerPlasticity model, and
steps the strain path while committing history with update_state:
def run_case(
confinement_pressure: float,
material: FrictionalMaterial,
n_steps: int = 32,
axial_strain_final: float = -0.025,
chara_length: float = 0.75,
) -> Dict[str, List[float]]:
"""Run one displacement-controlled triaxial-compression case."""
dtype = torch.float64
device = torch.device("cpu")
mesh = gen_cube(
left=0.0,
right=1.0,
bottom=0.0,
top=1.0,
front=0.0,
back=1.0,
chara_length=chara_length,
)
mesh.points = mesh.points.to(device=device, dtype=dtype)
model = DruckerPragerPlasticity.from_mesh(mesh, material=material)
points = mesh.points
result: Dict[str, List[float]] = {
"axial_strain": [],
"axial_stress_compression_kpa": [],
"mean_pressure_compression_kpa": [],
"alpha_max": [],
"elastic_trial_f_kpa": [],
}
for axial_strain_value in torch.linspace(0.0, axial_strain_final, n_steps, device=device, dtype=dtype):
eps_diag = triaxial_strain_path(axial_strain_value, confinement_pressure, material)
u = affine_displacement(points, eps_diag).detach().clone().requires_grad_(True)
energy = model.energy(
point_data={"displacement": u},
element_data=model.element_data_from_history(),
)
# Calling backward confirms the potential is differentiable, even though
# this affine driver has no unconstrained degrees of freedom to optimize.
if energy.requires_grad:
energy.backward()
model.update_state(u)
sigma = model.mean_stress(u)
p_comp = -sigma.trace() / 3.0
sigma_axial_comp = -sigma[2, 2]
f_elastic = elastic_trial_yield_value(eps_diag, material)
result["axial_strain"].append(float(-axial_strain_value))
result["axial_stress_compression_kpa"].append(float(sigma_axial_comp / 1.0e3))
result["mean_pressure_compression_kpa"].append(float(p_comp / 1.0e3))
result["alpha_max"].append(float(model.max_alpha()))
result["elastic_trial_f_kpa"].append(float(f_elastic / 1.0e3))
return result